How I Built a Fully Automated AI Learning Machine: n8n + NotebookLM Turns Any Topic Into Podcasts, Videos & Quizzes
Notion
Imagine this: you give a system any topic — a political science chapter, a tech article, a history lesson — and it automatically generates a deep-dive podcast, an explainer video, a quiz, and study notes. No manual editing. No recording equipment. No video editing software.
That's exactly what I built. And in this tutorial, I'll show you how to build it yourself.
Why This Exists
🧠 The Problem: Learning is passive. You read a textbook, watch a lecture, highlight some notes — and forget 80% within a week. Active learning through multiple formats (audio, video, quizzes) dramatically improves retention. But creating those formats manually is insanely time-consuming.
The Solution: An automated pipeline that takes any source material and transforms it into multiple learning formats — without you lifting a finger after the initial trigger.
Here's what my system produces from a single input:
The Architecture: How It All Connects

The system runs on a self-hosted homelab using Proxmox virtualization, but the concepts apply to any server or cloud setup. Here's the bird's-eye view:
graph TD
A["Trigger: Schedule / Form / API"] --> B["n8n Workflow Engine"]
B --> C["Fetch Content from Notion / Text / URL"]
C --> D["NotebookLM CLI"]
D --> E["Create Notebook"]
E --> F["Add Source Material"]
F --> G["Deep Research (40-50+ web sources)"]
G --> H["Generate Quiz"]
G --> I["Generate Podcast (EN/NE)"]
G --> J["Generate Video (Explainer/Brief)"]
H --> K["Save to NAS"]
I --> K
J --> K
K --> L["Upload to YouTube"]
K --> M["Send via Email"]
L --> N["Auto SEO Metadata"]The Tech Stack
Real-World Example 1: Daily Political Science Newsletter
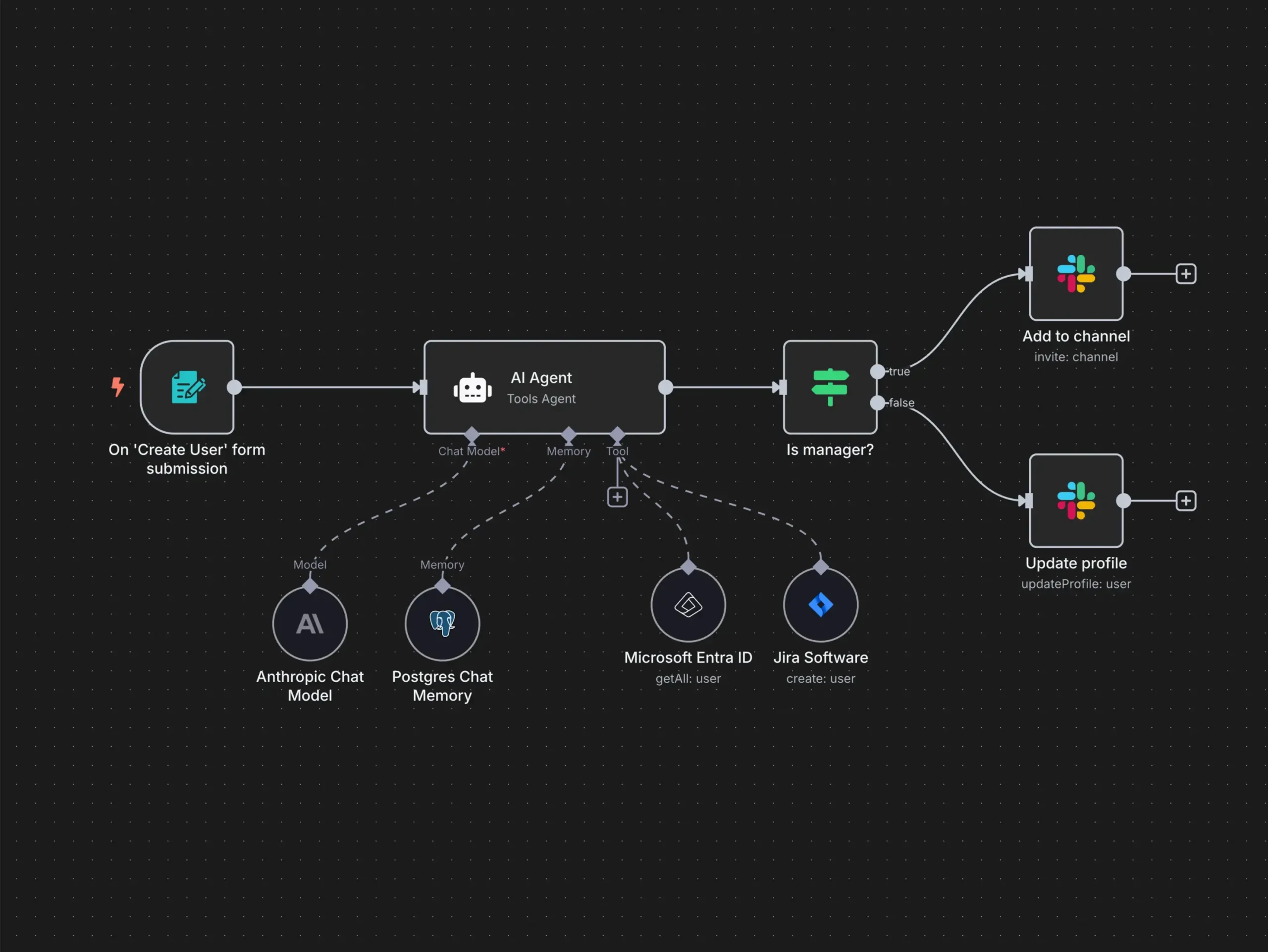
This is the pipeline that runs every single day at 4 AM without any human intervention.
What it does:
- Picks the next chapter from a 77-chapter political science curriculum stored in Notion
- Fetches the full chapter content via the Notion API
- Creates a NotebookLM notebook and adds the chapter as a source
- Runs deep research — NotebookLM searches the web, pulls 40-50+ sources, and synthesizes everything
- Generates a 5-question quiz (JSON format)
- Generates two podcasts — English deep-dive + Nepali deep-dive
- Generates three videos — English explainer, English brief/shorts, Nepali explainer
- Saves everything to the NAS
- Builds a styled HTML email with the chapter, quiz, and podcast player link
- Sends the email via Gmail
- Triggers a separate workflow to upload videos to YouTube with viral SEO metadata
The n8n Workflow
graph LR
A["4 AM Cron"] --> B["Read State"]
B --> C["Fetch Notion Chapter"]
C --> D["Convert to HTML"]
D --> E["Run Generation Script"]
E --> F["Build Email"]
F --> G["Send via Gmail"]
G --> H["Update Chapter Index"]
H --> I["Trigger YouTube Upload"]The core magic happens in the generation script, which chains NotebookLM CLI commands:
#!/bin/bash
# Simplified version of the generation pipeline
DAY=$1
TITLE=$2
CHAPTER_FILE=$3
OUT_DIR="/mnt/nas-politics/day-${DAY}-${SLUG}"
# 1. Create notebook
NOTEBOOK_ID=$(notebooklm create "$TITLE" --json | jq -r '.id')
# 2. Add chapter as source
notebooklm source add "$CHAPTER_FILE" --json -n $NOTEBOOK_ID
# 3. Deep research (pulls 40-50+ web sources automatically)
notebooklm source add-research "$TITLE" \
--mode deep --import-all -n $NOTEBOOK_ID
# 4. Generate quiz
notebooklm generate quiz "Create a 5-question MCQ quiz" \
--quantity standard --difficulty medium \
--json --wait --retry 3 -n $NOTEBOOK_ID
# 5. Generate English podcast
notebooklm generate audio \
"Create an engaging deep-dive podcast about $TITLE" \
--format deep-dive --language en \
--json --retry 3 -n $NOTEBOOK_ID
# 6. Generate explainer video
notebooklm generate video \
"Create a cinematic explainer video about $TITLE" \
--format explainer --style classic --language en \
--json --retry 3 -n $NOTEBOOK_ID
# 7. Download all artifacts to NAS
notebooklm download quiz "$OUT_DIR/quiz.json" --format json
notebooklm download audio "$OUT_DIR/podcast-en.mp3"
notebooklm download video "$OUT_DIR/video-en.mp4"Output structure on NAS:
day-42-separation-of-powers/
├── chapter.md # Source content
├── quiz.json # 5 MCQ questions
├── podcast-en.mp3 # English deep-dive podcast
├── podcast-ne.mp3 # Nepali deep-dive podcast
├── video-en.mp4 # English explainer (5-10 min)
├── video-en-brief.mp4 # English shorts (1-2 min)
├── video-ne.mp4 # Nepali explainer
├── youtube-metadata.json # Auto-generated viral SEO
└── metadata.json📊 Result: 77 chapters x 7 outputs each = 539 pieces of learning content generated fully automatically. The system has been running daily since launch, producing podcasts, videos, and quizzes while I sleep.
Real-World Example 2: On-Demand Video Creator

Beyond the daily newsletter, I built a web form that lets anyone create learning videos on demand.
How it works:
- Visit the form at your n8n server URL
- Choose a content source: Notion page, free text, or URL
- Pick video types: explainer, brief, or both — in English or Nepali
- Select research depth: none, light, or deep
- Choose a visual style: classic, whiteboard, anime, watercolor, retro-print, and more
- Assign a YouTube playlist
- Hit submit — get a "Processing..." response immediately
- 30-60 minutes later: videos appear on your YouTube channel, fully tagged and SEO-optimized
Video Styles Available
The Prompt Intelligence
The system doesn't just pass your topic to NotebookLM blindly. It uses a local LLM (qwen3:8b via Ollama) to:
- Read the first 3000 characters of your article
- Generate a content-specific cinematic video prompt
- Create viral YouTube titles, descriptions, and tags
- Adapt the tone for different video types (explainer vs. shorts)
Real-World Example 3: Study Podcast Generator for College Courses

This is my personal favorite. I use this for my actual college courses.
The Problem:
Your professor assigns 50 pages of dense reading. You have three other classes. There's no time to deeply engage with the material.
The Solution:
- Parse the syllabus — extract week-by-week reading assignments with page numbers
- Extract pages from the textbook PDF — automatically pull just the assigned pages
- Feed into NotebookLM — the extracted PDF becomes the sole source (no external research — keeps it focused on the actual assigned reading)
- Generate a study podcast — a 20-minute deep-dive discussion of exactly what you need to know for class
# Extract pages from textbook (Python + PyMuPDF)
import fitz
OFFSET = 37 # front matter pages
doc = fitz.open("Norton-Anthology-Vol2.pdf")
new_doc = fitz.open()
new_doc.insert_pdf(doc, from_page=686+OFFSET, to_page=708+OFFSET)
new_doc.save("week-10-reading.pdf")
# Generate study podcast via NotebookLM CLI
notebooklm create "Week 10: Virginia Woolf" --json
notebooklm source add "week-10-reading.pdf" --json
notebooklm generate audio \
"Create a deep-dive podcast about this reading. \
Focus on key themes, literary techniques, \
important passages, and discussion points." \
--format deep-dive --language en --json --retry 3🎧 How I use it: I listen to the AI podcast on my commute before class. When discussion starts, I already know the key themes, notable passages, and critical arguments. My participation and comprehension went through the roof.
Step-by-Step: Build This Yourself

Prerequisites
- A server (Proxmox, bare metal, or cloud VM)
- n8n installed (self-hosted or cloud)
- Python 3.11+
- A Google account (for NotebookLM)
Step 1: Install NotebookLM CLI
pip install notebooklm-py
# Authenticate (one-time — saves browser state)
notebooklm auth loginThis opens a browser window where you log into Google. The session is saved to ~/.notebooklm/storage_state.json.
Step 2: Set Up n8n
If you're self-hosting:
# Install via npm
npm install -g n8n
# Or via Docker
docker run -d --name n8n \
-p 5678:5678 \
-v ~/.n8n:/home/node/.n8n \
n8nio/n8nStep 3: Create Your Generation Script
This is the core script that n8n will call. Here's a simplified, reusable version:
#!/bin/bash
set -euo pipefail
TITLE="$1"
CONTENT_FILE="$2"
OUT_DIR="$3"
LANGUAGE="${4:-en}"
mkdir -p "$OUT_DIR"
# Create notebook
NB_ID=$(notebooklm create "$TITLE" --json | jq -r '.id')
echo "Notebook: $NB_ID"
# Add source
notebooklm source add "$CONTENT_FILE" --json -n "$NB_ID"
# Wait for source to be ready (critical!)
while true; do
STATUS=$(notebooklm source list --json -n "$NB_ID" | \
jq -r '.[0].status')
[ "$STATUS" = "ready" ] && break
echo "Source status: $STATUS — waiting..."
sleep 5
done
# Optional: Deep research
notebooklm source add-research "$TITLE" \
--mode deep --import-all -n "$NB_ID" 2>/dev/null || true
# Generate podcast
AUDIO_ID=$(notebooklm generate audio \
"Create an engaging deep-dive podcast about $TITLE" \
--format deep-dive --language "$LANGUAGE" \
--json --retry 3 -n "$NB_ID" | jq -r '.artifact_id')
# Generate video
VIDEO_ID=$(notebooklm generate video \
"Create a cinematic explainer about $TITLE" \
--format explainer --style classic --language "$LANGUAGE" \
--json --retry 3 -n "$NB_ID" | jq -r '.artifact_id')
# Generate quiz
QUIZ_ID=$(notebooklm generate quiz \
"Create a quiz to test understanding of $TITLE" \
--quantity standard --difficulty medium \
--json --wait --retry 3 -n "$NB_ID" | jq -r '.artifact_id')
# Wait for artifacts
notebooklm artifact wait "$AUDIO_ID" --timeout 2400 -n "$NB_ID"
notebooklm artifact wait "$VIDEO_ID" --timeout 2400 -n "$NB_ID"
# Download everything
notebooklm download audio "$OUT_DIR/podcast.mp3" \
-a "$AUDIO_ID" -n "$NB_ID"
notebooklm download video "$OUT_DIR/video.mp4" \
-a "$VIDEO_ID" -n "$NB_ID"
notebooklm download quiz "$OUT_DIR/quiz.json" \
--format json -a "$QUIZ_ID" -n "$NB_ID"
echo "Done! All files in $OUT_DIR"Step 4: Wire It Up in n8n
Create a workflow with these nodes:
- Trigger — Cron schedule, webhook, or manual
- Fetch Content — HTTP Request to Notion API, or read from file
- Execute Script — Run your generation script via Execute Command node
- Process Output — Parse the generated files
- Distribute — Email, YouTube upload, Notion update
⚠️ Important n8n setting: Set your execution timeout to at least 7200 seconds (2 hours). NotebookLM generation can take 30-60 minutes for video. In your n8n service file:
Step 5: Add YouTube Auto-Upload
The system can automatically upload generated videos to YouTube with SEO-optimized metadata:
# Auto-generate viral YouTube metadata using local LLM
import requests, json
def generate_metadata(title, content_snippet):
prompt = f"""Generate YouTube metadata for a video titled \"{title}\".
Content: {content_snippet[:2000]}
Return JSON with: title, description, tags (15-20), category.
Make it SEO-optimized and click-worthy."""
resp = requests.post("http://localhost:11434/api/generate",
json={"model": "qwen3:8b", "prompt": prompt})
return json.loads(resp.text)More Use Cases You Can Build
The pipeline is topic-agnostic. Here are ideas to get you started:
For Students
- Textbook-to-Podcast: Extract chapters → generate study podcasts (my college workflow)
- Lecture Notes to Quiz: Upload class notes → auto-generate practice quizzes
- Research Paper Explainer: Feed a dense paper → get a 10-minute video breakdown
For Content Creators
- Blog-to-Video Pipeline: Write a blog post in Notion → auto-generate a YouTube video
- Newsletter Companion: Every newsletter gets an audio version for subscribers who prefer listening
- Course Creation: Turn your expertise into a structured video series automatically
For Teams & Organizations
- Onboarding Content: Company docs → training podcasts and videos for new hires
- Meeting Summaries: Meeting notes → podcast recap for people who missed it
- Product Docs: Technical docs → explainer videos for customers
For Language Learning
- Multilingual Content: Generate the same content in multiple languages (English + Nepali in my case)
- Pronunciation Practice: AI podcasts in target language with natural conversation flow
The NotebookLM Secret Sauce

What makes NotebookLM special for this use case:
Deep Research Mode
When you use --mode deep --import-all, NotebookLM doesn't just use your uploaded source. It:
- Searches the web with 2-3 intelligent queries
- Pulls 40-50+ relevant sources
- Synthesizes everything with your original content
- Creates a richer, more comprehensive output
Podcast Quality
The AI-generated podcasts feature two hosts having a natural conversation. It's not a robotic text-to-speech — it's genuinely engaging, with:
- Natural pauses and reactions
- "Oh that's interesting!" moments
- Questions and follow-ups between hosts
- Humor and personality
Video Styles
NotebookLM offers multiple visual styles for video generation, each suited for different content types. From clean motion graphics (classic) to hand-drawn illustrations (whiteboard) to colorful anime aesthetics.
Rate Limiting & Reliability
The system handles NotebookLM's rate limits gracefully with exponential backoff:
def generate_audio_safe(notebook_id, prompt, max_retries=5):
for attempt in range(max_retries):
try:
return notebooklm.generate_audio(prompt)
except RateLimitError:
wait = min(60 * (2 ** attempt), 3600)
print(f"Rate limited. Waiting {wait}s...")
time.sleep(wait)
raise Exception("Max retries exceeded")Key Lessons & Gotchas
Things That Bit Me (So They Don't Bite You)
1. Source status matters. After adding a source to NotebookLM, it enters a preparing state. If you try to generate content before the source is ready, generation will fail with GENERATION_FAILED. Always poll for ready status.
2. n8n timeout defaults are too low. Default execution timeout is 3600 seconds. Video generation can take 45-60 minutes. Set N8N_RUNNERS_TASK_TIMEOUT=7200 or higher.
3. NotebookLM rate limits are real. If you hit rate limits, use exponential backoff. For persistent rate limiting, wait about an hour before retrying.
4. Videos download in the background. Video artifacts can take 10-15 minutes to download. Use nohup and log output to a file so the main workflow can continue.
5. Quiz format matters. Always use --format json for quizzes. HTML format is unreliable in email templates and harder to parse programmatically.
6. For study podcasts, skip external research. When generating podcasts from textbook readings, do NOT add deep research. It dilutes the focus with tangential information. Only use your extracted PDF as the source.
The Numbers
What's Next

This system is a living project. Here's what's on the roadmap:
- Claude API integration — Replace template-based video prompts with Claude-generated, content-specific cinematic prompts
- HeyGen avatar videos — Add a human avatar presenting the content with auto-generated B-roll
- Multilingual expansion — Add Hindi, Spanish, and French podcast generation
- Interactive quizzes — Turn generated quizzes into web-based interactive assessments
- Notion auto-publish — Generated content automatically creates blog posts with embedded media
Try It Yourself
You don't need a homelab to start. Here's the minimum viable version:
# 1. Install the CLI
pip install notebooklm-py
# 2. Authenticate
notebooklm auth login
# 3. Create your first automated podcast
notebooklm create "My First AI Podcast" --json
notebooklm source add "your-article.pdf" --json
notebooklm generate audio \
"Create an engaging podcast about this content" \
--format deep-dive --language en --json --retry 3
# 4. Download it
notebooklm download audio "my-podcast.mp3"That's it. Three commands and you have an AI-generated podcast from any document.
Scale it up with n8n when you're ready to automate.
🚀 The big takeaway: We're living in an era where a single person can build an entire educational content studio that runs 24/7, produces multi-format learning content in multiple languages, and distributes it globally — all for $0 in running costs. The only limit is your imagination about what to teach.
Built with n8n, Google NotebookLM, Proxmox, and a lot of late nights. Questions? Drop a comment or reach out.
Share this post
Help this article travel further
One tap opens the share sheet or pre-fills the post for the platform you want.